手写爬虫实战

图片爬虫
学习了爬取网页技巧和正则表达式之后, 通过图片爬取来进行一次实战练习.
情景: 京东商城手机图片爬取
我的手机依然是高二购买的IPhone5S, 手机到现在已经整整用了3年了. 每当我看到新的手机时, 总是眼馋的不行, 奈何口袋里没有足够的银两, 只能时不时逛一逛商城解除以下眼馋~ 所以, 今天的任务就是爬取京东商城所有的手机图片.
第一步, 获得URL
- 登陆京东主页
- 搜索==>手机, 进入手机商场页面, 里面有各种手机图片.
- 因为有很多页, 拉动到最下面,点击第二页观察一下URL
- URL : http://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E6%89%8B%E6%9C%BA&cid2=653&cid3=655&page=3&s=72&click=0
- 可以看到, URL 中 有字段 page = 3. 推断修改page的值就可以访问所有手机页面.
- 由此获得了所有 包含手机图片的URL.
第二步, 观察页面源码, 找到图片的描述.
- 鼠标再页面中点击右键, 单机查看源码
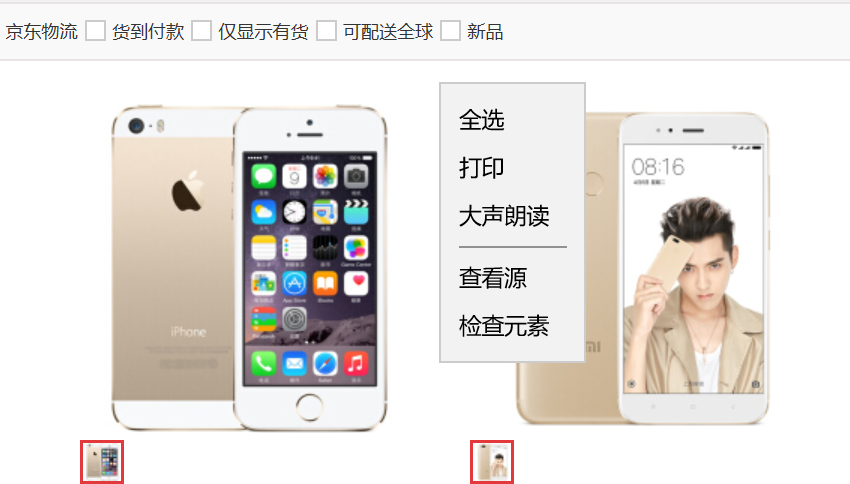
可以看到html源码后, 查找图片的描述, 这里的技巧是:
观察原网页, 找到任意图片下面的描述, 如 小米 Note3 ….xxx
再源码页面 Ctrl+f 查找这些文字, 观察文字附近的标签, 找到:
<img width="220" height="220" class="err-product" data-img="1" src="//img10.360buyimg.com/n7/jfs/t12859/355/1502498371/155178/f5e7e927/5a213b0aNcbdbb90a.jpg" />
这个就是图片标签
第三步, 根据图片的描述, 设计图片的正则表达式
参考正则表达式 , 可以得到图片的正则表达式为
pat = '<img width="220" height="220" class="err-product" data-img="1" (.*?) />' |
当然, 这还不是图片资源网址应该有的格式, 我们需要的只是 src后面的部分 , 所以需要再pat匹配之后的结果, 继续匹配
pat2 = '//img.+?\.jpg' |
第四步, 根据正则表达式获得图片资源的链接, 爬取并保存图片
import re |
效果图
爬取一个网页上所有的URL
套路基本和之前一样, 这个相对简单, 直接上代码.
import urllib.request |
结果:
hox@ColdCode:~/work-place/pystudy/crawTest$ python3 code.py
url:www.csdn.net
http://blog.csdn.net/carson_ho/article/details/79314325#comment_form
http://blog.csdn.net/X8i0Bev/article/details/79071576
http://blog.csdn.net/u013088062/article/details/50893901
http://blog.csdn.net/zuochao_2013/article/details/56024172
http://blog.csdn.net/blockchain_lemon/article/details/79395162
http://blog.csdn.net/b644ROfP20z37485O35M/article/details/79055019
http://gitbook.cn/gitchat/geekbook/5a582543e286423809d4a7e5?utm_source=sy18022402
http://blog.csdn.net/tMb8Z9Vdm66wH68VX1
http://blog.csdn.net/a2Ni5KFDaIO1E6/article/details/79070518
http://blog.csdn.net/dqcfkyqdxym3f8rb0/article/details/79402975
http://blog.csdn.net/b644ROfP20z37485O35M/article/details/79055019#comment_form
http://blog.csdn.net/hanli1992/article/details/79380262
http://qualcomm.csdn.net/
http://blog.csdn.net/csdnnews/article/details/79395044
http://blog.csdn.net/FYGu18/article/details/79063230#comment_form
http://blog.csdn.net/FYGu18/article/details/79063230
http://huawei.csdn.net/
http://blog.csdn.net/MOY37RQW1JarN33BgZk/article/details/79051044#comment_form
http://blog.csdn.net/meyh0x5vDTk48P2/article/details/79072666
http://blog.csdn.net/kXYOnA63Ag9zqtXx0
http://blog.csdn.net/g6U8W7p06dCO99fQ3/article/details/79064119
http://blog.csdn.net/age12v/article/details/79071815#comment_form
….
爬取糗事百科上的所有段子
如果上面两个例子略显无趣, 下面这个例子可算是相当又用了. 省去一页一页的手动翻页, 将所有段子爬取下来. 貌似很有趣的样子.
- 段子再html中 的位置如下
<div class="content"> |
代码如下
import re |