Urllib和URLError异常处理(1)

Hox Zheng
Feb 10, 2018
Python中的Urllib库
Urllib是Python提供的一个用于操作URL的模块.
快速使用Urllib爬取网页
导入模块(Python3)
import urllib.request |
打开并且爬取一个网页
file = urllib.request.urlopen('http://www.baidu.com') |
读取内容的常见方法
- file.read() 读取文件的全部内容. 把读取到的内容赋值给一个bytes变量.
- file.readlines() 读取文件的全部内容, 与read不同的是, readlines会把读取到的内容赋值给一个列表变量. 若要读取全部内容, 推荐这种方式.
- file.readline() 读取文件的一行内容.
所以读取的代码可以是:
import urllib.request |
- 把爬取到的内容存储到了baidu.html 文件中.
直接存储
- 有一个直接的API可以将html存储到文件
import urllib.request |
- urlretrieve执行的过程中, 会缠身一些缓存, 如果我们想清楚这些缓存信息. 可以使用urlcleanup()
urllib.request.urlcleanup() ## 清除产生的缓存 |
其他api
file.info() ## 返回当前环境的有关信息 |
有些时候, 一些URL字符不符合标准. 比如中文,和其他一些字符. 需要编码:
urllib.request.quote('http://www.sina.com.cn') |
浏览器模拟
有些网站为了防止别人恶意采集其信息. 所以进行了一些反爬虫设置. 比如CSDN. 这个时候, 我们可以设置一些Headers信息, 模拟成浏览器访问它们, 就不会出现 403错误!!!!
方法就是设置User-Agent, 获得UserAgent的方法
- 打开浏览去,进入百度.
- 按F12, 打开network表项.
- 点击百度一下, 产生一个动作. 然后单机 “www.baidu.com”
- 将右方的标签切换到Headers, 下拉,可以找到User-Agent.
- 把内容拷贝出来.
Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36
使用add_header() 添加报头:
import urllib.request |
超时设置
urlopen可以设置超时参数,timeout. 如果超出预定的时间, 会抛出异常.
import urllib.request |
HTTP 协议请求实战
如果要进行客户端与服务端之间的消息传递, 我们可以使用HTTP协议请求进行.
HTTP 请求类型:
- GET请求: GET请求会通过URL网址传递信息, 可以直接在URL中写上要传递的信息, 也可以由表单进行传递. 如果使用表单进行传递, 这表单中的信息会自动转换为URL地址中的数据, 通过URL地址传递.
- POST请求: 可以向服务器提交数据吗是一种比较主流也是比较安全的数据传递方式, 比如在登陆时, 经常使用POST请求发送数据.
- DELETE请求: 请求服务器删除一个资源.
- HEAD请求: 请求获取对应的HTTP报头信息.
- OPTIONS请求: 可以获取当前URL所支持的类型.
GET请求实例分析
GET请求通过URL传递信息, 所以如果要使用GET请求, 思路如下:
- 构建对应的URL地址, 该URL地址包含GET请求的字段名和字段内容等信息. 并且URL地址满足GET请求格式, 即”http://网址?字段名1=字段内容1&字段2=字段内容2&….”
- 以对应URL为参数, 构建Request对象
- 通过urlopen()打开构建的Request对象
- 按需求进行后续的处理操作, 比如读取网页的内容, 将内容写入文件等.
百度搜索GET请求
百度搜索关键词的时候, 实际上是提交了一个GET请求.
- 打开浏览器, 进入百度主页. 输入 hello. 单机百度一下.
- 页面跳转, 出现搜索结果.
- 观察url内容如下
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=baidu&wd=hello&oq=hello&rsv_pq=c47c6c7600056239&rsv_t=5390XZslzjINYKp%2F8sMmU8HCPgnIeQuz%2BzAn9WhDv6CQwPfjausL0x%2BoShY&rqlang=cn&rsv_enter=0 |
- 可以看到, 关键词出现在 wd = hello 这里, 所以我们简化URL
https://www.baidu.com/s?wb=hello |
- 在地址栏输入后回车, 结果依然是hello的搜索结果, 说明简化结果正确, 我们确定了URL. 所以构建的URL为:
url = "https://www.baidu.com/s?wb=" + keyword |
- 剩下的工作:
#encoding=utf-8 |
- 测试:
hox@ColdCode:~/work-place/pystudy$ python3 head.py |
- 发现, 如果关键词是英文, 正常. 如果出现中文, 会出现编码问题, 这里可以通过之前学习过的方法解决.
#encoding=utf-8 |
POST请求实例分析
我们在进行注册,登陆等操作的时候, 基本上都会遇到POST请求. 但是, 由于登陆需要用到Cookie的知识, 所以关于如何登陆这一块, 将在后面学习. 现在, 只需要掌握如何使用POST表单传递信息即可.
- 感谢教材的作者提供了一个POST表单测试的网页.
作者: 韦伟 教材: 精通Python网络爬虫[机械工业出版社]
实现思路如下
- 设置好URL网址
- 构建表单数据, 并使用urllib.parse.urlencode对数据进行编码处理.
- 创建Request对象, 参数包括URL地址和要传递的数据.
- 使用add_header()添加头信息, 模拟浏览器进行爬取.
- 使用urllib.request.urlopen()打开对应的Request对象, 完成信息的传递.
- 后续处理, 比如读取网页的内容, 将内容写入文件.
具体步骤
- 设置好对应的URL地址, 这里处理的页面是 http://www.iqianyue.com/mypost
- 然后构建我们需要的表单数据, 在该网页上右击”查看页面源代码”, 找到对应的form表单部分,如图:

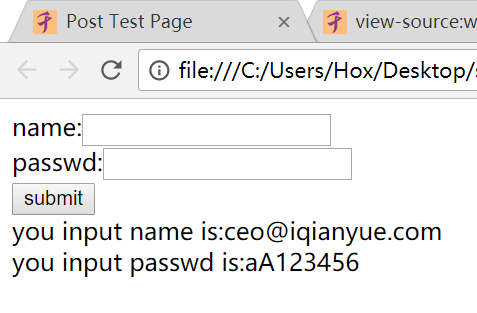
- 所以,我们要构造的数据可以分为{“name”:”ceo@iqianyue.com”,”pass”:”aA123456”}
- 设置好表单, 然后使用 urllib.parse.urlencode对数据进行编码处理.
- 创建Request对象, 添加表头.
- 整合之后, 完整的爬虫代码如下图所示:
#encoding=utf-8 |
- 正确的执行结果应该如下:
总结
这家伙很懒, 什么都没有留下.